This article explores a hybrid learning algorithm applied to
the problem of Information Intake Filtering (IIF). Information
Intake refers to information that impinges upon users. For example,
users intake electronic mail and news. A distinction is made between
Information Retrieval (IR) and IIF: in IR the user is actively
searching, while a user reacts to information intake. IIF entails
prioritizing objects in a conceptual in-basket. The advent of
large-scale hypertext publishing systems [Nelson]
portends an increase in the volume of information intake. For
instance, events generated by linking and new version creation
can notify a reader or author of changes made to a hyperdocument.
IIF tools are needed to save time. Additionally, good filtering
techniques make it possible to keep abreast of changes in a larger
domain than one would otherwise examine because the bandwidth
is reduced to a manageable level.
A personal, adaptive recommendation system is described which uses an exit-question to rate documents. Ratings collected in this way have the property of being minimally articulated, which is an advantage when preferences are difficult to describe. The ratings are used to prioritize future information intake as well as to create shared recommendations. A hybrid learning algorithm is described that is oriented toward efficiently handling information in the form of evolving hypertext, mail and news.
An extensible set of document features such as author, author organization, ratings from earlier readers, etc., is used. These features are used independently and conjunctively to create boolean functions which model what the user finds interesting or uninteresting.
Groups of people can automatically share ratings of documents while the learning algorithm determines which users make common ratings. The goal of this work is to direct readers' attention in a self-correcting way with as little user effort as possible, and to utilize ratings automatically to connect readers whose interests concur.
Keywords: Genetic Algorithms, Adaptive user interface, Hypertext, Document prioritizing, Information Filtering.
Reprints: http://www.baclace.net
In this article the term "information intake" is
used to refer to information that is delivered to a user by open
ended processes that might include mail, news and hypertext change
notifications. The user reacts to information intake. This is
distinguished from IR where the user is active in a problem-solving
mission. The central difference between IR and IIF is that in
IIF accurately modeling a user over a long period of time is very
important. In IR the main concern revolves around transitory user
queries.
This article explores a connectionist approach to IIF. The hybrid learning algorithm described here draws upon Genetic Algorithms, Neural Networks and Agoric Systems [Miller] to achieve quick convergence at the cost of little cpu time.
An IIF tool is a time saving device; if one had an infinite amount of time to handle all information intake, then IIF would not be necessary. The goal of IIF is the prioritizing of information, which assists the direction of human attention. Prioritizing can take the form of highlighting items of extreme importance or deleting items that are considered junk.
A large-scale hypertext publishing system would result in an increase of available information over the amount with which users of electronic mail and Usenet news are familiar. This increase can come about merely due to the use of links. Further, the potential lowering of the cost of publishing with the incentive of royalties will arguably increase the raw amount of available information. Judging from past technological trends in publishing, decreasing costs tend to increase the information intake of the average person. A hyperdocument can trigger information intake by becoming larger due to the addition of links or the creation of new versions. If a reader/author is notified of these changes, then an inflow of information is created. Because of this, it will be necessary to prioritize hyperdocuments at the level of links.
Prioritizing can throw away what is considered junk and highlight what is considered very important. New intake that is not recognized in any way must be considered "no comment" and passed on to the user without any recommendation.
At this point two kinds of intake can be distinguished: potential and actual. Potential intake is what is delivered automatically to an "in-basket." After filtering is used, prioritized, actual intake remains, which is what the user sees. In the remainder of this article, this distinction will not be made, but the context should indicate whether potential or actual intake is being referenced.
This article describes a document-rating system tailored to
optimizing IIF. The recognition of authors and correlation of
document-reviewer ratings are of primary importance. Keyword recognition
is also used. Sifting through information intake can be made much
easier when author recognition and reviewer recommendation correlation
are done with as little user effort as possible. Reducing the
amount of discipline necessary to prioritize can mitigate information
overload.
The Information Lens system [Malone] used encoded knowledge in the form of frames to recognize messages and classify them. In creating the system, Malone's team discovered that many of the difficult natural language problems could be avoided by using "semi-structured templates". The system would classify some mail intake, for instance, as "bug fix request" or "seminar notice". Then, the Information Lens directed the mail to an appropriate folder, which in itself is an act of classification. The problems with this approach are that it requires mail senders to use templates and a catalog of templates must be designed.
"Broadcatching," the idea of having computational agents that search for interesting material, is part of Network Plus [Bender]. In this system, concurrently broadcasted closed captions and television news were used in conjunction with keyword matching to generate customized news. Wire service news stories were also integrated into the system. Network Plus demonstrated the feasibility of triggering news capture by using only keywords, although the system as a whole was oriented toward presentation production. The Network Plus system did not incorporate user feedback.
Document search by relevance feedback [Salton] is a search-by-example technique that searches multiple times based upon a user's rating of retrieved documents as being relevant or irrelevant. The idea is that suitable terms for a search can be discovered in a process that is much like a discourse. Maron underscored the idea that a perfect description of what a user finds relevant does not exist, and that any information about user preferences are only clues that can point one in the right direction [Maron]. Relevance feedback is used in the present work.
Recent work on genetic algorithms for information retrieval [Gordon] focused on document redescription. Gordon used a process by which descriptions of documents are modified over time in an attempt to find "identifiable regularities in a large enough set of inquirers' requests for a given document". This approach can improve access of documents in a relatively stable database with a large number of users. However, this technique is not suitable to information intake at the personal level, where preferences and priorities can be quite idiosyncratic. A centralized user model is difficult to share across information-vendor boundaries.
Natural language queries and query recognition using plausible inference have had some success [Croft]. Such semantic analysis approaches seem to be very attractive. Unfortunately, this approach requires knowledge bases that have yet to be developed. In the present work, the use of a hybrid learning algorithm simplifies the cost of development and provides significant filtering and recommendation without expert systems. Such expert systems are also predicated on the ability to create reusable user models in an environment that is more and more fragmented; large hypertext publishing systems will encourage fragmentation and plurality due to linking and the lower cost of publishing.
Other recent work using Bayesian reasoning was found to be
computationally complex [Frisse] and suggests
that alternatives need to be analyzed. In addition, Frisse and
Cousins write, "As we learn, we often see an abrupt change
in the desirability of information units. Information that was
once invaluable can suddenly become obvious, and one must ensure
that one's program recognizes when presentation of an information
unit becomes a nuisance." This realization was made independently
early in the present work and influenced the design of the learning
algorithm to have rapid convergence and to eschew concerns about
appropriate, long-term model convergence, which has been criticized
as being computationally intractable [Valiant].
Opinion-capture in a window system, as suggested by Drexler, can be done with an exit question mapped onto a "dismiss" selection for sections of a hyperdocument [Drexler]. Such exit reviews can be shared to support automatically both shared human recommendation and a learning system that adapts to the reader.
Richard Dawkins [Dawkins] recently made available a program he called "Blind Watchmaker" which accompanied a book by the same name. This program uses genetic algorithms for evolving symmetrical and asymmetrical bit maps that appear to be depictions of icons or insects. It presents nine pictures of which the center one is the "current" bug and the surrounding bugs differ by, at most, one gene. The user can point to any of the surrounding bugs and the program makes that the center picture, surrounding it by more bugs. Using this method, a user can walk through the genetic landscape of possible bugs. Although this program was written to elucidate the mechanisms of Darwinian evolution, I think it demonstrates an interesting user interface technique: it is a non-articulated search mechanism (strictly speaking, this is really "minimal-articulated"). The user does not necessarily need a mental model of the genotype and its development of bugs, but can nonetheless search a large, multidimensional space. A non-articulated search mechanism is useful when the search space is complex and difficult to describe. It has been argued[Polanyi] that most of human knowledge cannot be articulated, so this seems a good path to explore. In addition, the selection that causes the search step is quick; it is only a mouse gesture. This technique is used in the present system for modeling the level of interest or priority of intake. However, instead of bugs evolving, a pool of simple agents is evolved that prioritize intake.
In the IIF, documents with "no comment" or positive ratings are presented to the user. The term document here is meant to denote the smallest retrievable chunk of information that can be viewed. Thus, a hyperdocument composed of many documents linked together in various ways can be decomposed and edited by the intake filter to present a custom hyperdocument to the reader.
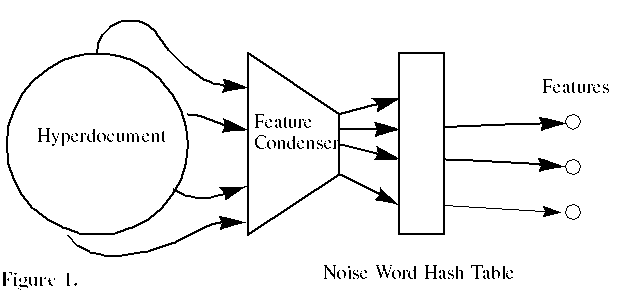
Features are extracted from the intake being analyzed. The amount of raw information in a document is reduced after feature extraction, so this is referred to as a "feature condenser" in this article (see Fig. 1). The feature condenser is considered to be an extensible module. Due to the extensibility, the current implementation is designed to allow flexible expansion. All features are represented as type-value pairs. For any particular type, zero or more occurrences are allowed. A noise-word filter is used to screen out commonly occurring words that are not good discriminators. For example, the word "the" has a high frequency of occurrence and is not useful for prioritizing. Figure 1 depicts the process by which features are extracted and filtered by a feature condenser.
The hybrid learning algorithm presented here has five main attributes: population seeding, quick convergence, conjunctive learning, garbage collection and computational efficiency. These will be covered one at a time after discussing the overall structure. The general approach taken here is connectionist, rather than symbolic or statistical. This is inspired by work done by Farmer [Farmer] in comparing Neural Networks, Classifier Systems and Immune Networks; such systems appear to be more similar than different.
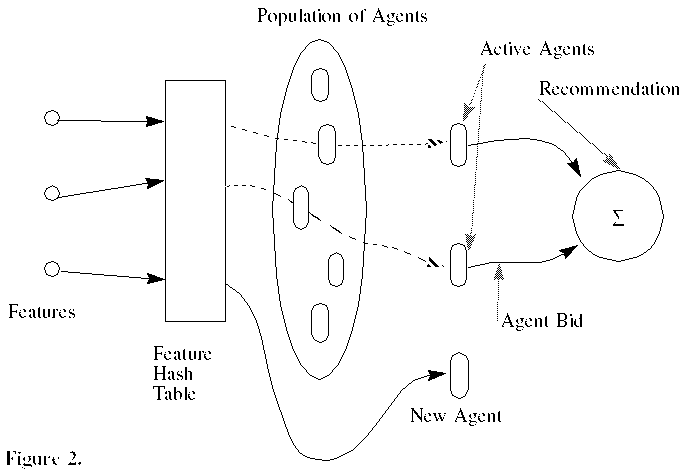
The present learning model consists of a population of agents that contribute to an estimated level of interest. The use of the term "agent" here is similar to Minsky's[Minsky]; an agent is very simple. An agent is termed to be sensitive to or triggered by features in a document being evaluated for recommendation. Agents sensitive to conjunctions of features are termed conjunctive agents while agents sensitive to one feature are termed simple agents. An agent also has a store of "money," a bid in the range [-1..+1], and a bid learning rate. The agents cooperate and compete for correct predictions of a user's actual interest rating. This is an incremental algorithm in that the population learns with each rating provided by the user. The population of agents is private to a user.
Figure 2 shows how features trigger agents. In this diagram, two agents contribute toward a total recommendation and one agent is created to be sensitive to a newly-found feature.
The agents are created from features found in documents. That is, the population is seeded from samples of actual user ratings. This means that a user starts with a pool of zero agents and as information intake is rated, agents are created and entered into the population. Agents are created with unique features; duplicates are not allowed. This design choice eliminates a combinatorial explosion of conjunctions with duplicate features. Seeding the population in this manner is equivalent to relevance feedback with a uniform weight based on the document rating.
New agents are given "birth money" which is a grant that keeps an agent alive long enough to determine whether it is useful. This is a tunable parameter that can be used to keep the population small.
Learning at the individual level is used to lessen the need for multiple agents that are sensitive to the same feature, which is the case in Genetic Algorithms (GA) where many individuals must compete along some dimension in order for evolution to take place. The work of Hinton and Nowlan [Hinton] and Belew [Belew] was drawn upon to achieve this. Belew distinguishes between evolution and learning. The GA causes evolution on a broad scale while learning at the individual level is a quick acting adaptation mechanism. By having agents that can change their bets, adaptation is quicker than it would be when using GA evolution alone. Active agents adjust their bid after the document is rated by the user. Each agent has a learning rate which is essentially a bias that can put more emphasis on the new user rating versus old bid. After payoff, each agent recalculates its bid:
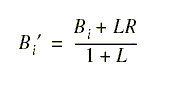
Agoric Open Systems as described by Miller and Drexler [Miller] is an economic model used for optimizing
computational resources. The Derby system[Kaehler]
inspired a payoff function used to enforce competition among the
agents and to account for the survival and death of agents. The
interesting facet of this payoff function is that it forces competition
among agents even though they cooperate in a solution. An agent
i has error ![]() :
:
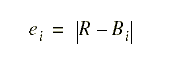
The total error for n agents is:
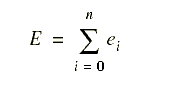
To purchase a recommendation in this simulated economy, 1 dollar
is paid to the n active agents that participate in a particular
recommendation. This money must be distributed among the agents
such that the agents that most accurately predict the rating R
are paid the most, while the agents with the most error are actually
charged for their bid. The reason for pumping a fixed amount of
money into the economy is that it puts some pressure on the agents
to be efficient by causing crowding. That is, a payout proportional
to the number of active agents would encourages the creation of
too many agents while a scarcity of new money will make agents
compete for dollars among each other. The payoff of agent i, ![]() is:
is:
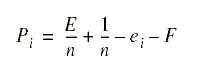
where ![]() is the "error bonus"
that pays out more for the larger overall error, but pays less
when more agents are active. The
is the "error bonus"
that pays out more for the larger overall error, but pays less
when more agents are active. The ![]() term
is a fixed share of pay for activation. Agents are penalized for
their particular error
term
is a fixed share of pay for activation. Agents are penalized for
their particular error ![]() and are also charged
a fixed activation fee F. This amounts to a payoff where agents
equally share the 1 dollar paid out, but an agent that is nearly
correct while the overall error is high gets more money proportional
to the size of the overall error. The activation fee F is used
to weed out agents that are no better than random.
and are also charged
a fixed activation fee F. This amounts to a payoff where agents
equally share the 1 dollar paid out, but an agent that is nearly
correct while the overall error is high gets more money proportional
to the size of the overall error. The activation fee F is used
to weed out agents that are no better than random.
The total payoff ![]() is:
is:
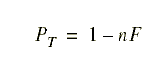
where the total activation charge nF reduces the amount of
money (1 dollar) put into the economy assuming that there is no
reified recipient for the activation charge. This relationship
points out some limits for the tunable parameter F; it cannot
be so large that no agents get paid, but it should be tuned so
that ![]() is equal to 0 for some maximum number of active
agents that is considered feasible.
is equal to 0 for some maximum number of active
agents that is considered feasible.
Agents can be charged "rent" at some interval. This rent decreases uniformly the amount of money all agents have. If an agent ends up never being triggered again, it will be considered destitute when it runs out of money. Agents that are no better than random also become destitute.
Destitute agents can be handled in three ways: (1) The agent can remain in the population as a "pruned" search branch. When that feature is detected, it is then thrown out to prune searching for conjunctive agents. (2) The agent's features can become incorporated into the noise-word filter used in the feature condenser to weed out words that are consistently useless for distinguishing articles. (3) The agent can be garbage collected. If the feature arises again, a new agent will be created to give it another chance to be useful. Birth money interacts with options (1) and (2): birth money establishes an upper bound on the complexity of conjunctions based on simple features. For option (3), there is no complexity limit because a feature can create an agent whenever it is present in an article. Birth money is independent of the learning potential in option (3). A combination of (2) and (3) seems a reasonable approach in retrospect; however, option (1) was used in the present implementation.
After each document rating, the active agents are randomly selected and combined in a GA crossover. This is a simplification of standard GA systems that ordinarily represent a gene as a bit string. Usually the bit string is equivalent to some parameter that is part of an optimization or recognition problem. In the present algorithm, discrete feature type-value pairs are stored directly as the genes or genotype. This reflects the discrete nature of words in natural languages. GA crossover takes two gene bit strings and combines them to produce offspring. There are many crossover techniques, and the canonical method is done by selecting a crossover point in the bit string and copying bits from one parent to the offspring from one section of the bit string, and then copying the rest of the bits from the other parent. In the present algorithm, GA crossover is a simple matter of concatenating a list of feature type-value pairs from each parent agent. Again, the rationale here is that discrete nature of features that necessitates this simplification.
Crossover creates agents that are sensitive to conjunctions of features, i.e., the agent is triggered only when all features are present. (This structure is reminiscent of classifier systems [Holland] but differs in that agents do not form hierarchies and the credit assignment problem is avoided. This design choice was made to trade off memory for cpu. Mutation, the probability of a random bit change in the offspring, is not used in the present learning algorithm.)
Public ratings are stored in a local area network database. The ratings associate a user name, a unique document identifier and a rating chunked into 5 categories for the ranges [-1,-.5), [-.5,0), 0, (0,.5], (.5,1]. This allows an approximation of a rating to be shared by eliminating the need for agents sensitive to number ranges. This was used for the Usenet news test described below. In a hypertext publishing system, it would be possible to use links to associate ratings with documents. During the feature condensing process, the public rating database is indexed by the unique document identifier and the public ratings found are included with the document features.
Several techniques help speed up the IIF. First, hash tables were used whenever possible to speed up agent lookup. Second, it is desirable to promote quick convergence with few generations of the genetic algorithm. Thus, crossover is used to create conjunctions, but individuals remain alive unless they run out of money by making too many wrong recommendations. This differs from the usual GA that completely regenerates the population using selection, crossover and mutation after each evaluation. Only active agents are eligible for crossover and a tunable number of conjunctions are used.
The ELK (Extension Language Kernel) version of Scheme written by Oliver Laumann (at Nixdorf Computer AG, Teles GmbH, Technical University of Berlin, Germany) was used. A custom object oriented extension was added. Feature types and values were hashed to find agents. Agents then competed and cooperated in predicting what the user's rating will be. Agents cooperated in that their recommendations are summed, but they also competed in that a fixed payoff was given and losers may have given money to winners.
Each agent was represented as an object that could receive messages to get the features it was sensitive to, pay the agent, do crossover, etc. A population class contained instances of agents in a hash table (indexed by features) while instances of a review class were used to associate a particular review with a document.
The use of Scheme made representation of the agents and initial prototyping easy, however, Scheme is slow at lexical analysis due to its basic string copy semantics. This can be avoided by using an unnatural representation for strings and tokens.
Several experiments were tried on the system. The first experiment was a series of evaluations where the user rated all documents as +1. This was learned precisely without a single error. The second experiment was a "change of mind" case where after responding positively to a set of features, the user reversed his or her opinion. In this case, the learning result was very good; the rating was reversed immediately with the only error being the single case where the user changed his or her mind. This was tried after short and long series of high interest ratings by the user and no cumulative effect occurred to cause resistance in changing the model.
A more difficult case was constructed for the third test. This is an Exclusive Or problem such that conjunctions are required to separate the solutions and initial learning results are very deceptive. In this example, four samples were repeated over and over (see Table 1).
|
Example |
F1 | F2 | F3 | F4 |
User Rating |
| E1 | 1 | 0 | 1 | 0 | +1 |
| E2 | 1 | 0 | 0 | 1 | -1 |
| E3 | 0 | 1 | 1 | 0 | -1 |
| E4 | 0 | 1 | 0 | 1 | +1 |
In table 1, F1-F4 represent features and an entry of 1 indicates the presence of the feature and 0 the absence of the feature. E1-E4 are the four examples that are to be learned. This is a deceptive case because E1 seems to indicate that features F1 and F3 are desirable, but E2 indicates that F1 is not desirable when a new feature, F4, is present. In E3, more is revealed and a new feature, F2, is learned to be not desirable while F3 is present contradicting the E1 case where F3 seemed desirable. Finally, E4 creates one more contradiction for F4. This example cannot be learned by simple summation of bids from simple agents that are sensitive to F1-4; and, indeed, experiments show that such simple agents eventually go broke. This is equivalent to a one-layer neural network that cannot separate the input samples for Exclusive Or without the use of a second layer that effectively adds another dimension making the samples linearly separable.
The results of the third experiment indicated that the Exclusive Or problem can be learned in as few as 7 presentations, that is, the sequence {E1, E2, E3, E4, E1, E2, E3}. This is possible when the learning rate is globally fixed at 1.0. When the learning rate was randomly selected at agent birth, 8.75 presentations were required on average. This indicates that the learning rate could be globally fixed to guarantee quick convergence.
The birth money, a globally-tuned parameter, needed to be at least 3.0 for the third experiment. That is, for a problem as complex as this, 3.0 units of money are required to sustain all simple agents until the conjunctions are created. Eventually the simple agents run out of money because they are consistently deceived.
To test further the usefulness of the present information-intake filter, Usenet news articles were used as a sample information source. Usenet news is organized in a hierarchy and uses links to indicate cross postings and temporal ordering (although the temporal ordering is relative to the uucp site). This provides the sufficiently large volume of data for which an information-intake filter would be useful.
It was found that the IIF was very helpful for throwing out articles that were not of interest. For newsgroups that were particularly uninteresting, this was very helpful. For newsgroups that are "mostly interesting," the IIF appropriately prioritized the articles. Although this is based on a subjective evaluation, these promising results plus the three experiments indicate that useful prioritization is possible.
In an extensive evaluation of a full text search information retrieval system [Blair], it was found that on average only 20% of the relevant documents were retrieved. This underscores the need for human annotation and linking, made possible use by of hypertext systems. The use of public ratings in the present system captures and utilizes ratings in a way that is very easy to use.
When using an information-intake filter, it is convenient to have a mental model of the system. This model does not have to be an accurate representation, but can be similar to the tacit mental model one has when training pets. That is, one should not be capricious when making ratings otherwise the user model would behave in the same manner. The newsreader that was constructed with the intake filter also had a "why" command which listed the agents that bid positively and negatively (although the overall bid was greater than or equal to 0). This was found to be enlightening for the tuning process and was occasionally surprising.
It is important to note that the prioritizing of documents adapts to a user's style. For instance, if a user never wants any intake deleted, then ratings less than 0 can be avoided.
An interesting aspect of this IIF design is that the population of agents contain information that can be regarded as private. Because of this, the population must be stored in a relatively secure filesystem. Public ratings can also be considered private; users may be sensitive to the fact that a particular document was viewed. The present implementation allows the user to turn off the sharing of ratings as desired to accommodate this concern.
For hyperdocuments, agents that are sensitive to the types of links attached to a document would be helpful. Such agents could rate schemas of documents based upon particular structures. The work of Croft and Turtle [Croft2] explores a Bayesian inference technique that is used to correlate query relevance with link structure. This points to an interesting area of research.
Additional features like article age and length should be taken into consideration. To provide for more specific ratings, it should be possible to point to a feature and make a special rating (e.g., rating the author only).
User ratings are very subjective; they represent the mental state of the reader. Because of this, it is possible to add mood switches to the user interface. For instance, a user could indicate urgency level (high, low, don't-care) [McClary]. Associations between article length, keywords, and author can be made with this mental state to present a reader with material appropriate for his or her current mood.
Future hypertext publishing systems will undoubtedly charge for the amount of data delivered to an end user. This presents an optimization problem in that users should be charged for what they read, but should not be charged at the same rate for indexing. This could be solved by creating a market for indices and condensed features. A reader's personal intake filters could check for the existence of a condensed version of the information, and use that for a basis of recommendation. Using this technique, it would be possible to distribute the cost of condensing a hyperdocument across many readers and reduce the end-user cost of examining large document spaces.
The connectionist hybrid learning algorithm described here explores a method for IIF. The user model is emergent and also supports sharing of ratings via a public rating database. In the absence of conflicting examples, the learning algorithm has been found to adapt to user preferences based on simple features in one presentation. When conflicting (deceptive) examples are rated, the algorithm can separate them with conjunctions in a reasonable number of presentations. This makes it possible for a localized model of user preferences to be constructed that is independent of the data-vendor, thus affording accuracy and privacy.
I would like to thank Mark Miller for encouragement and comments. Thanks also go to Jacque Baclace, Carl Tollander, Joel Voelz, Doug Merritt, Ted Nelson, Rick Mascitti, Robert Jellinghaus, Dan Rosenfeld, Andy Beals and Marc LeBrun.
[Belew] R. K. Belew. "When Both Individuals and Populations Search: Adding Simple Learning to the Genetic Algorithm." Proceedings of the Third International Conference on Genetic Algorithms, ed. J. Schaffer, pp. 34-41, 1987, Morgan Kaufmann, San Mateo, CA.
[Bender] Bender, W., P. Chesnais. "Network Plus". SPSE Electronic Imaging Devices and System Symposium, January, 1988.
[Blair] Blair, D. C., M. E. Maron. "An Evaluation of Retrieval Effectiveness for a Full-Text Document-Retrieval System." Communications of the ACM, 28(3): 289-299, (March 1985).
[Croft1] Croft, W. B., T. J. Lucia. "Retrieving Documents by Plausible Inference: An Experimental Study." Information Processing & Management, Vol 25, No. 6, pp. 599-614 (1989).
[Croft2] Croft, W. B., H. Turtle. "A Retrieval Model for Incorporating Hypertext Links." Hypertext 89 Proceedings, ACM SIGCHI Bulletin, November 1989, pp. 213-224.
[Drexler] Drexler, E. "Hypertext Publishing and the Evolution of Knowledge." Social Intelligence, Vol. 1, No. 2, pp.87-120; Revised edition.
[Dawkins] Dawkins, R. "The Blind Watchmaker." Norton, 1986.
[Farmer] Farmer, D. "Rosetta Stone for Connectionism." Physica D, Elsevier Science Publishers, North-Holland, 42:153-187, (1990)
[Frisse] Frisse, M. E., S. B Cousins. "Information Retrieval from Hypertext: Update on the Dynamic Medical Handbook Project." Hypertext 89 Proceedings, ACM SIGCHI Bulletin, pp. 199-212 November 1989.
[Gordon] Gordon, M. "Probabilistic and Genetic Algorithms for Document Retrieval." Communications of the ACM, 31(10):1208-1218, (October, 1988).
[Hebb] Hebb, D. O. "The Organization of Behaviour." Wiley, NY, 1949.
[Hinton] G. E. Hinton and S. J. Nowlan. "How Learning can Guide Evolution." Complex Systems, 1:495-502, 1987.
[Holland] Holland, J. "Adaptation in Natural and Artificial Systems." University of Michigan Press, Ann Arbor, MI, 1975.
[Kaehler] Kaehler, T., H. Nash, M. S. Miller. "Betting, Bribery, and Bankruptcy-A Simulated Economy that Learns to Predict." IEEE CompCon Proceedings, pp. 357-361, 1989.
[Malone] Malone, T., K. Grant, F. Turbak, S. Brobst, M. Cohen, "Intelligent Information-Sharing Systems." Communications of the ACM, 30(5):390-402, (May, 1987).
[Maron] Maron, M. E. "Associative Search Techniques versus Probabilistic Retrieval Models." Journal of the American Society for Information Science, pp. 308-310, September, 1982.
[McClary] McClary, M., Xanadu Operating Company, personal communication.
[Miller] Miller, M. S., K. E. Drexler. "Markets and Computation: Agoric Open Systems." The Ecology of Computation, ed. B. A. Huberman, Elsevier Science Publishers, North-Holland, 1988.
[Minsky] M. Minksy. "Society of Mind." Simon and Shuster, NY, 1985.
[Nelson] Nelson, T. "Literary Machines." Mindful Press, Sausalito, CA, 1987.
[Polanyi] Polanyi, M. "Personal Knowledge." University of Chicago Press, 1958.
[Salton] G. Salton. "The SMART Retrieval System--Experiments in Document Processing." Prentice-Hall, Englewood Cliffs, NJ, 1971.
[Scheme-IEEE] Draft Standard for the Scheme Programming Language, IEEE P1178D5, October 1990.
[Valiant] Valiant, L. "A theory of the learnable." Communications of the ACM, 27(11):1134-1144 (November, 1984).